Quels sont les encodages de caractères comme ANSI et Unicode, et comment sont-ils différents?
ASCII, UTF-8, ISO-8859 ... Vous avez peut-être vu ces singes étranges circuler, mais que faire? ils signifient réellement? Continuez votre lecture en expliquant ce qu'est l'encodage des caractères et comment ces acronymes se rapportent au texte brut que nous voyons à l'écran
Building Blocks
Quand nous parlons de langage écrit, nous parlons de lettres comme éléments constitutifs des mots, qui ensuite construire des phrases, des paragraphes, et ainsi de suite. Les lettres sont des symboles qui représentent des sons. Quand vous parlez de langage, vous parlez de groupes de sons qui se rassemblent pour former une sorte de sens. Chaque système linguistique a un ensemble complexe de règles et de définitions qui régissent ces significations. Si vous avez un mot, c'est inutile à moins de savoir de quelle langue il s'agit et de l'utiliser avec d'autres qui parlent cette langue.

(Comparaison des scripts Grantha, Tulu et Malayalam, Image de Wikipédia)
Dans le monde des ordinateurs, nous utilisons le terme «caractère». Un caractère est une sorte de concept abstrait, défini par des paramètres spécifiques, mais c'est l'unité fondamentale du sens. Le latin 'A' n'est pas le même qu'un 'alpha' grec ou un 'alif' arabe parce qu'ils ont des contextes différents - ils sont de langues différentes et ont des prononciations légèrement différentes - donc nous pouvons dire qu'ils sont des caractères différents. La représentation visuelle d'un personnage s'appelle un "glyphe" et différents ensembles de glyphes sont appelés "polices". Les groupes de caractères appartiennent à un "ensemble" ou un "répertoire".
Lorsque vous tapez un paragraphe et que vous changez la police, vous ne changez pas les valeurs phonétiques des lettres, vous changez leur apparence. C'est juste cosmétique (mais pas sans importance!). Certaines langues, comme l'ancien égyptien et le chinois, ont des idéogrammes; ceux-ci représentent des idées entières au lieu de sons, et leurs prononciations peuvent varier dans le temps et la distance. Si vous substituez un caractère à un autre, vous substituez une idée. C'est plus qu'un simple changement de lettre, ça change un idéogramme.
Encodage des caractères

(Image de Wikipedia)
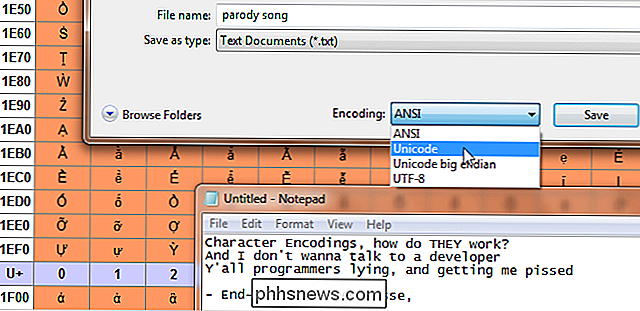
Lorsque vous tapez quelque chose sur le clavier ou que vous chargez un fichier, comment l'ordinateur sait-il afficher? C'est à ça que sert l'encodage de caractères. Le texte sur votre ordinateur n'est pas réellement des lettres, c'est une série de valeurs alphanumériques appariées. L'encodage de caractères agit comme une clé pour laquelle les valeurs correspondent à quels caractères, tout comme l'orthographe dicte quels sons correspondent à quelles lettres. Le code Morse est une sorte de codage de caractères. Il explique comment les groupes d'unités longues et courtes telles que les bips représentent des caractères. En code Morse, les caractères sont uniquement des lettres, des chiffres et des points d'arrêt en anglais. De nombreux encodages de caractères informatiques se traduisent par des lettres, des chiffres, des accents, des signes de ponctuation, des symboles internationaux, etc.
Souvent, sur ce sujet, le terme «pages de codes» est également utilisé. Ce sont essentiellement des encodages de caractères utilisés par des sociétés spécifiques, souvent avec de légères modifications. Par exemple, la page de code Windows 1252 (anciennement connue sous le nom ANSI 1252) est une forme modifiée de l'ISO-8859-1. Ils sont principalement utilisés en tant que système interne pour désigner les codages de caractères standard et modifiés qui sont spécifiques aux mêmes systèmes. Au début, l'encodage des caractères n'était pas si important parce que les ordinateurs ne communiquaient pas entre eux. Avec l'importance croissante de l'Internet et la mise en réseau, il est devenu de plus en plus important de nos vies quotidiennes sans que nous nous en rendions compte.
Beaucoup de types différents
(Image de sarah sosiak)
Il y a beaucoup de codages de caractères différents, et il y a beaucoup de raisons à cela. Le codage de caractères que vous choisissez d'utiliser dépend de vos besoins. Si vous communiquez en russe, il est logique d'utiliser un codage de caractères qui supporte bien le cyrillique. Si vous communiquez en coréen, alors vous voudrez quelque chose qui représente bien Hangul et Hanja. Si vous êtes un mathématicien, alors vous voulez quelque chose qui a bien représenté tous les symboles scientifiques et mathématiques, ainsi que les glyphes grecs et latins. Si vous êtes un farceur, vous pourriez peut-être bénéficier d'un texte à l'envers. Et, si vous voulez que tous ces types de documents soient affichés par une personne, vous voulez un encodage assez commun et facilement accessible.
Jetons un coup d'oeil à quelques-uns des plus communs.

(Extrait de la table ASCII, Image de asciitable.com)
- ASCII - Le code standard américain pour l'échange d'information est l'un des anciens codages de caractères. Il a été initialement conçu sur la base de codes télégraphiques et a évolué au fil du temps pour inclure plus de symboles et certains caractères de contrôle non-imprimés, désormais obsolètes. Il est probablement aussi basique que vous pouvez obtenir en termes de systèmes modernes, car il est limité à l'alphabet latin sans caractères accentués. Son encodage à 7 bits ne permet que 128 caractères, ce qui explique pourquoi plusieurs variantes non officielles sont utilisées dans le monde entier
- ISO-8859 - Le groupe d'encodage de caractères le plus largement utilisé par l'Organisation internationale de normalisation est le numéro 8859 Chaque codage spécifique est désigné par un numéro, souvent précédé d'un nom descriptif, par exemple ISO-8859-3 (latin-3), ISO-8859-6 (latin / arabe). C'est un sur-ensemble d'ASCII, ce qui signifie que les 128 premières valeurs de l'encodage sont les mêmes que ASCII. Cependant, il s'agit d'un jeu de 8 bits et de 256 caractères, ce qui permet de créer un tableau beaucoup plus large de caractères, chaque codage spécifique se concentrant sur un ensemble de critères différents. Latin-1 incluait un tas de lettres et de symboles accentués, mais fut remplacé plus tard par un ensemble révisé appelé Latin-9 qui inclut des glyphes mis à jour comme le symbole de l'Euro.
(Extrait du script tibétain, Unicode v4, unicode.org)
- Unicode - Cette norme d'encodage vise l'universalité. Il comprend actuellement 93 scripts organisés en plusieurs blocs, avec beaucoup d'autres dans les travaux. Unicode fonctionne différemment des autres jeux de caractères: au lieu de coder directement un glyphe, chaque valeur est dirigée vers un «point de code». Ce sont des valeurs hexadécimales qui correspondent à des caractères, mais les glyphes sont fournis séparément par le programme. , comme votre navigateur Web. Ces points de code sont généralement représentés comme suit: U + 0040 (qui se traduit par «@»). Les codages spécifiques sous la norme Unicode sont UTF-8 et UTF-16. UTF-8 tente de permettre une compatibilité maximale avec ASCII. C'est 8 bits, mais permet à tous les caractères via un mécanisme de substitution et plusieurs paires de valeurs par caractère. Les fossés UTF-16 offrent une compatibilité ASCII parfaite pour une compatibilité 16 bits plus complète avec la norme.
- ISO-10646 - Il ne s'agit pas d'un encodage réel, mais d'un jeu de caractères Unicode standardisé par l'ISO. C'est surtout important parce que c'est le répertoire de caractères utilisé par HTML. Certaines des fonctions les plus avancées fournies par Unicode qui permettent le classement et la droite à gauche à côté des scripts de gauche à droite sont manquantes. Pourtant, il fonctionne très bien pour une utilisation sur Internet car il permet l'utilisation d'une grande variété de scripts et permet au navigateur d'interpréter les glyphes. Cela rend la localisation un peu plus facile.
Quel encodage dois-je utiliser?
Eh bien, l'ASCII fonctionne pour la plupart des anglophones, mais pas pour beaucoup d'autres choses. Plus souvent, vous verrez ISO-8859-1, qui fonctionne pour la plupart des langues d'Europe occidentale. Les autres versions d'ISO-8859 fonctionnent pour des scripts cyrilliques, arabes, grecs ou autres. Toutefois, si vous souhaitez afficher plusieurs scripts dans le même document ou sur la même page Web, UTF-8 permet une bien meilleure compatibilité. Il fonctionne également très bien pour les personnes qui utilisent des signes de ponctuation, des symboles mathématiques ou des caractères spontanés, tels que des carrés et des cases à cocher.

(Plusieurs langues dans un document, Capture d'écran de gujaratsamachar.com)
inconvénients à chaque ensemble, cependant. ASCII est limité dans ses signes de ponctuation, donc il ne fonctionne pas incroyablement bien pour les modifications typographiquement correctes. Avez-vous déjà copié / collé à partir de Word pour avoir une étrange combinaison de glyphes? C'est l'inconvénient de l'ISO-8859, ou plus exactement, son interopérabilité supposée avec des pages de code spécifiques au système d'exploitation (nous nous intéressons à vous, Microsoft!). L'inconvénient majeur de l'UTF-8 est le manque de support approprié dans les applications d'édition et de publication. Un autre problème est que les navigateurs n'interprètent souvent pas et affichent simplement la marque d'ordre des octets d'un caractère codé en UTF-8. Cela entraîne l'affichage de glyphes indésirables. Et bien sûr, déclarer un encodage et utiliser des caractères d'un autre sans les déclarer / référencer correctement sur une page Web rend difficile le rendu correct des navigateurs et l'indexation appropriée des moteurs de recherche.
Pour vos propres documents, manuscrits, et ainsi de suite, vous pouvez utiliser tout ce dont vous avez besoin pour faire le travail. En ce qui concerne le Web, cependant, il semble que la plupart des gens soient d'accord pour utiliser une version UTF-8 qui n'utilise pas de marque d'octet, mais ce n'est pas tout à fait unanime. Comme vous pouvez le voir, chaque encodage de caractères a son propre usage, son contexte, ses forces et ses faiblesses. En tant qu'utilisateur final, vous n'aurez probablement pas à faire face à cela, mais vous pouvez maintenant faire un pas en avant si vous le souhaitez.

Comment réparer un conflit d'adresse IP
Vous avez déjà reçu un message d'erreur d'adresse IP lorsque vous allumez votre ordinateur ou que vous le sortez du mode veille? Cela se produit lorsque deux ordinateurs sur le même réseau LAN se retrouvent avec la même adresse IP. Lorsque cela se produit, les deux ordinateurs finissent par ne pas pouvoir se connecter aux ressources réseau ou effectuer d'autres opérations réseau.Voici le
Pourquoi est-il plus long de répondre à un mot de passe incorrect?
Avez-vous déjà saisi le mauvais mot de passe sur votre ordinateur et remarqué que cela prend quelques instants? répondre par rapport à entrer le bon? Pourquoi donc? Le post de questions et réponses de SuperUser d'aujourd'hui répond à la question d'un lecteur curieux. La session de questions et réponses d'aujourd'hui nous est offerte par SuperUser, une subdivision de Stack Exchange, un regroupement communautaire de sites Web Q & A.