Les données sur les disques durs peuvent-elles se dégrader sans avertissement sur les dommages?

Nous nous soucions tous de la sécurité et de l'intégrité de nos données et fichiers, mais il est possible qu'ils soient endommagés par un utilisateur sans une notification ou un avertissement d'aucune sorte sur le problème?
La séance de questions-réponses d'aujourd'hui nous est offerte par SuperUser, une subdivision de Stack Exchange, un regroupement communautaire de sites Web de questions-réponses.
Photo gracieuseté de généraliser (Flickr).
Le lecteur de SuperUser
Topo morto veut savoir si les données sur les disques durs peuvent se dégrader et être accessibles sans avertissement sur les dégâts:
Est-il possible que la dégradation physique d'un disque dur pourrait provoquer des "bits" à "flip" dans le contenu d'un fichier sans que le système d'exploitation ne remarque le changement et notifier l'utilisateur à ce sujet lors de la lecture du fichier? Par exemple, un "p" (binaire 01110000) dans un fichier texte ASCII peut-il passer à un "q" (binaire 01110001), puis lorsqu'un utilisateur ouvre le fichier, il voit "q" sans se rendre compte qu'un échec est survenu?
Je suis intéressé par les réponses concernant FAT, NTFS ou ReFS (si cela fait une différence). Je veux savoir si les systèmes d'exploitation en protègent les utilisateurs, ou si nous devrions vérifier nos données pour des variances entre les copies dans le temps.
Les données sur les disques durs peuvent-elles se dégrader et être consultées sans avertissement?
Réponse
Contributeur SuperUser Guntram Blohm a la réponse pour nous:
Oui, il y a une chose appelée bit pourriture. Mais non, cela n'affectera pas un utilisateur.
Lorsqu'un disque dur écrit un secteur sur les plateaux, il n'écrit pas simplement les bits de la même manière qu'ils sont stockés dans la RAM, il utilise un encodage pour s'assurer il n'y a pas de séquences du même bit qui sont trop longues. Il ajoute également des codes ECC qui lui permettent de réparer les erreurs affectant quelques bits et de détecter les erreurs qui affectent plus de quelques bits.
Lorsque le disque dur lit le secteur, il vérifie ces codes ECC et répare les données si nécessaire ( et si possible). Ce qui se passe ensuite dépend des circonstances et du micrologiciel du disque dur, qui est influencé par la désignation du disque.
- Si un secteur peut être lu et n'a pas de problème de code ECC, il est transmis au système d'exploitation
- Si un secteur peut être réparé facilement, la version réparée peut être écrite sur disque, relue, puis vérifiée pour déterminer si l'erreur était aléatoire (rayons cosmiques, etc.) ou s'il y a une erreur systématique avec le média.
- Si le disque dur détermine qu'il y a une erreur avec le média, il réattribue le secteur
- Si un secteur ne peut être ni lu ni corrigé après quelques tentatives de lecture (sur un disque dur qui est désigné comme un disque dur RAID), alors le disque dur abandonnera, réaffectera le secteur, et indiquera au contrôleur qu'il y avait un problème. Il s'appuie sur le contrôleur RAID pour reconstruire le secteur à partir des autres membres RAID et le réécrire sur le disque dur défaillant, qui le stocke ensuite dans le secteur réaffecté (ce qui, espérons-le, n'a pas de problème).
- Si un secteur ne peut pas être lu ou corrigé sur le disque dur d'un ordinateur de bureau, alors le disque dur s'engagera dans plus de tentatives pour le lire. Selon la qualité du disque dur, cela peut impliquer de repositionner la tête, en vérifiant s'il y a des bits qui retournent à plusieurs reprises, en vérifiant quels sont les bits les plus faibles, et quelques autres choses. Si l'une de ces tentatives réussit, le disque dur réallouera le secteur et réécrira les données réparées
C'est l'une des principales différences entre les disques durs vendus comme "desktop", "NAS / RAID" ou " vidéosurveillance "disques durs. Un disque dur RAID peut simplement abandonner rapidement et faire réparer le secteur par le contrôleur pour éviter la latence du côté de l'utilisateur. Un disque dur de bureau continuera à essayer encore et encore parce que l'attente de l'utilisateur quelques secondes est probablement mieux que de leur dire que les données sont perdues. Et un disque dur vidéo évalue les taux de données constants plus que la récupération d'erreur, car une image endommagée ne sera généralement pas remarquée.
Quoi qu'il en soit, le disque dur saura s'il y a eu pourriture du bit, il en récupérera typiquement, et s'il ne le peut pas, il indiquera au contrôleur qui à son tour dira au pilote qui indiquera alors le système d'exploitation. Ensuite, il appartient au système d'exploitation de présenter l'erreur à l'utilisateur et d'agir en conséquence. C'est pourquoi Cybernard dit:
- Je n'ai jamais été témoin d'une seule erreur, mais j'ai vu beaucoup de disques durs où des secteurs entiers ont échoué.
Le disque dur saura s'il y a un problème avec un secteur, mais il ne saura pas quels bits ont échoué. Un seul bit qui a échoué sera toujours intercepté par ECC
Veuillez noter que chkdsk et les systèmes de fichiers qui se réparent automatiquement n'abordent pas la réparation des données dans les fichiers. Ceux-ci sont ciblés à la corruption dans la structure du système de fichiers lui-même, comme une différence dans la taille d'un fichier entre l'entrée du répertoire et le nombre de blocs alloués. La fonction d'auto-réparation de NTFS détectera les dommages structurels et empêchera d'affecter davantage vos données, mais ne réparera aucune des données déjà endommagées.
Il y a, bien sûr, d'autres raisons pour lesquelles les données peuvent être endommagées. Par exemple, une mauvaise RAM sur un contrôleur peut altérer les données avant même qu'elles soient envoyées sur le disque dur. Dans ce cas, aucun mécanisme sur le disque dur ne détectera ou ne réparera les données, et cela peut être une raison pour laquelle la structure d'un système de fichiers est endommagée. Les autres raisons incluent les bogues logiciels, les coupures de courant lors de l'écriture sur le disque dur (même si cela est traité par la journalisation du système de fichiers) ou les pilotes de système de fichiers défectueux (le pilote NTFS sur Linux est en lecture seule depuis longtemps). pas documenté, et les développeurs n'ont pas confiance en leur propre code).
- J'ai eu ce scénario une fois où une application enregistrerait tous ses fichiers sur deux serveurs différents dans deux centres de données différents afin de conserver une copie de travail des données disponible en toutes circonstances. Après quelques mois, nous avons remarqué qu'environ 0,1% de tous les fichiers copiés ne correspondaient pas à la somme de contrôle MD5 que l'application stockait dans sa base de données. Cela s'est avéré être un câble fibre défectueux entre le serveur et le SAN.
Ces autres raisons expliquent pourquoi certains systèmes de fichiers, comme ZFS, conservent des informations de somme de contrôle supplémentaires afin de détecter les erreurs. Ils sont conçus pour vous protéger de beaucoup plus de choses qui peuvent aller mal que de la pourriture.
Avez-vous quelque chose à ajouter à l'explication? Sonnez dans les commentaires. Vous voulez lire plus de réponses d'autres utilisateurs de Stack Exchange? Découvrez le fil de discussion complet ici.
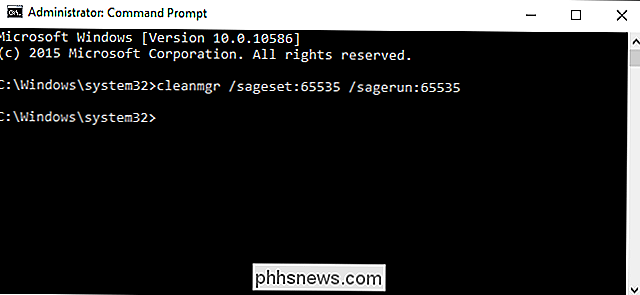
Comment activer les options cachées dans l'outil de nettoyage de disque de Windows
L'outil de nettoyage de disque existe depuis des années dans Windows. Il offre un moyen rapide de supprimer les fichiers temporaires, de cache et autres fichiers non essentiels pour vous aider à libérer de l'espace disque. Vous pouvez même l'utiliser pour supprimer les anciennes versions de Windows après une mise à niveau vers Windows 10.

Pourquoi ne pas vous connecter automatiquement à votre PC Windows
La connexion automatique à votre PC Windows ouvre un trou de sécurité. Lorsque vous activez les connexions automatiques, le mot de passe de votre compte Windows est stocké sur votre PC où n'importe quel programme avec un accès administrateur peut y accéder. Si vous utilisez un compte Microsoft pour vous connecter - ou réutilisez un mot de passe important.